Une étude publiée le 18 septembre dernier par des chercheurs de l’université Stanford révèle à quel point les secrets de GPT-4 et d’autres systèmes d’IA de pointe sont profonds et potentiellement dangereux.
Présentation de l'indice de transparence des modèles fondamentaux, Université de Stanford
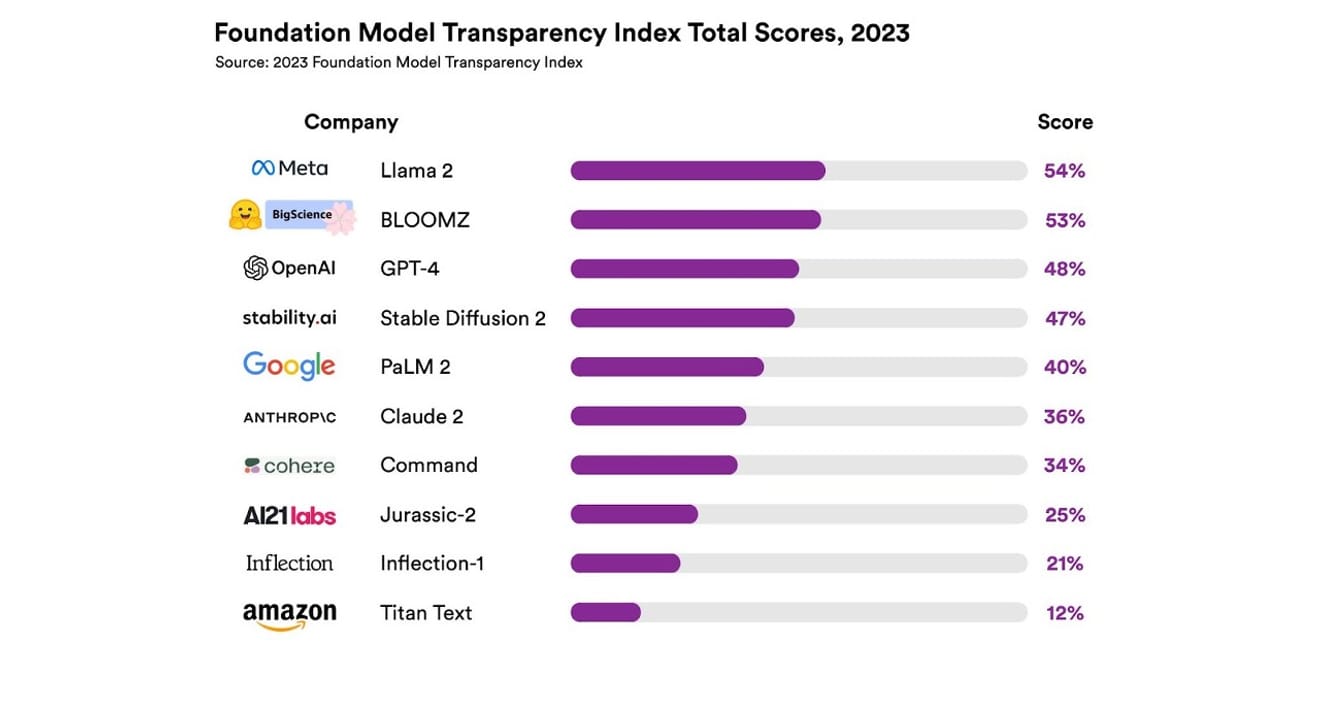
Ils ont examiné un total de 10 systèmes d’IA différents, la plupart étant des modèles linguistiques de grande taille (LLM), semblables à ceux utilisés pour ChatGPT et d’autres chatbots. Parmi eux figuraient des modèles commerciaux largement utilisés, tels que GPT-4 d’OpenAI, PaLM 2 de Google et Titan Text d’Amazon. Ils ont évalué leur transparence selon 13 critères, notamment le degré de transparence des développeurs quant aux données utilisées pour l’apprentissage des modèles (méthodes de collecte et d’annotation des données, inclusion ou non de documents protégés par le droit d’auteur, etc.). Ils ont également étudié si les informations relatives au matériel utilisé pour l’entraînement et l’exécution des modèles, aux frameworks logiciels utilisés et à la consommation énergétique des projets étaient accessibles au public.
Les résultats ont montré qu’aucun modèle d’IA n’a atteint plus de 54 % du seuil de transparence pour tous les critères mentionnés. Globalement, Titan Text d’Amazon a été considéré comme le moins transparent, tandis que Llama 2 de Meta a été désigné comme le plus ouvert. Il est intéressant de noter que Llama 2, un modèle open source qui représente un acteur majeur de la récente opposition entre modèles ouverts et fermés, n’a pas divulgué les données utilisées pour son apprentissage, ni les méthodes de collecte et de conservation de ces données. En d’autres termes, malgré l’influence croissante de l’IA sur notre société, le manque de transparence au sein du secteur est un phénomène généralisé et constant.
Cela signifie que le secteur de l’IA risque bientôt de devenir un domaine axé sur les bénéfices plutôt que sur le progrès scientifique, et qu’il pourrait conduire à un avenir monopoliste dominé par certaines entreprises.

Eric Lee/Bloomberg via Getty Images
Sam Altman, PDG d’OpenAI, a déjà rencontré des décideurs du monde entier pour leur expliquer cette nouvelle intelligence inconnue et les aider à concrétiser les réglementations correspondantes. Toutefois, s’il soutient en principe l’idée d’une organisation internationale chargée de superviser l’IA, il estime également que certaines règles restrictives, comme l’interdiction de tous les documents protégés par le droit d’auteur dans les ensembles de données, pourraient constituer des obstacles injustes. Il est clair que l’« ouverture » du nom de la société OpenAI s’est éloignée de la transparence radicale qu’elle avait initialement proposée.
Toutefois, les résultats du rapport de Stanford montrent qu’il n’est pas nécessaire que les entreprises maintiennent un tel secret sur leurs modèles respectifs pour des raisons de concurrence. En effet, ces résultats sont aussi un indicateur du manque de performance de presque toutes les entreprises. Par exemple, aucune entreprise ne fournirait de statistiques sur le nombre d’utilisateurs qui dépendent de ses modèles ou sur les régions ou les segments de marché qui utilisent ses modèles, affirme-t-on.
Au sein des organisations qui prônent l’open source, on dit souvent que « plus il y a d’yeux, plus vite les bogues sont trouvés » (loi de Linus). Les simples chiffres aident à identifier les problèmes et à trouver des solutions aux problèmes qui peuvent être corrigés.
Cependant, les pratiques open source ont également tendance à affaiblir progressivement la position et la reconnaissance sociale et professionnelle des entreprises ouvertes, à l’intérieur et à l’extérieur de ces entreprises, il est donc inutile d’insister aveuglément sur ce point. Plutôt que de s’attarder sur le cadre des modèles ouverts ou fermés, il serait préférable de concentrer le débat sur la nécessité de progressivement élargir l’accès externe aux « données » qui sous-tendent les modèles d’IA.

Pour le progrès scientifique, la garantie de la reproductibilité (Reproducibility) des résultats de recherche est essentielle. Sans une concrétisation des moyens de garantir la transparence des principaux composants de la création de chaque modèle, le secteur risque de rester bloqué dans une situation monopolistique fermée et stagnante. Il faut garder à l’esprit que cela doit être considéré comme une priorité absolue, compte tenu de la rapidité avec laquelle l’IA s’immisce dans tous les secteurs d’activité, aujourd’hui et à l’avenir.
Il est devenu essentiel que les journalistes et les scientifiques comprennent les données, et pour les décideurs, la transparence est une condition préalable aux efforts politiques prévus. Pour le grand public, la transparence est également importante, car en tant qu’utilisateur final des systèmes d’IA, il peut être à la fois auteur et victime de problèmes potentiels liés aux droits de propriété intellectuelle, à la consommation d’énergie et aux biais. Sam Altman affirme que le risque d’extinction de l’humanité dû à l’IA doit devenir une priorité mondiale, au même titre que d’autres risques sociétaux comme les pandémies ou les guerres nucléaires. Cependant, il ne faut pas oublier que la survie de notre société, qui entretient une relation saine avec l’IA en développement, est une condition préalable à l’apparition de ces situations dangereuses.
*Cet article est la version originale d’une chronique publiée dans le journal électronique Electronic News le 23 octobre 2023.
Références
Commentaires0