Het onderzoek dat op 18 september door onderzoekers van Stanford University werd gepubliceerd, laat zien hoe diepgaand en potentieel gevaarlijk de geheimen van GPT-4 en andere geavanceerde AI-systemen zijn.
Introductie van de Foundation Model Transparency Index, Stanford University
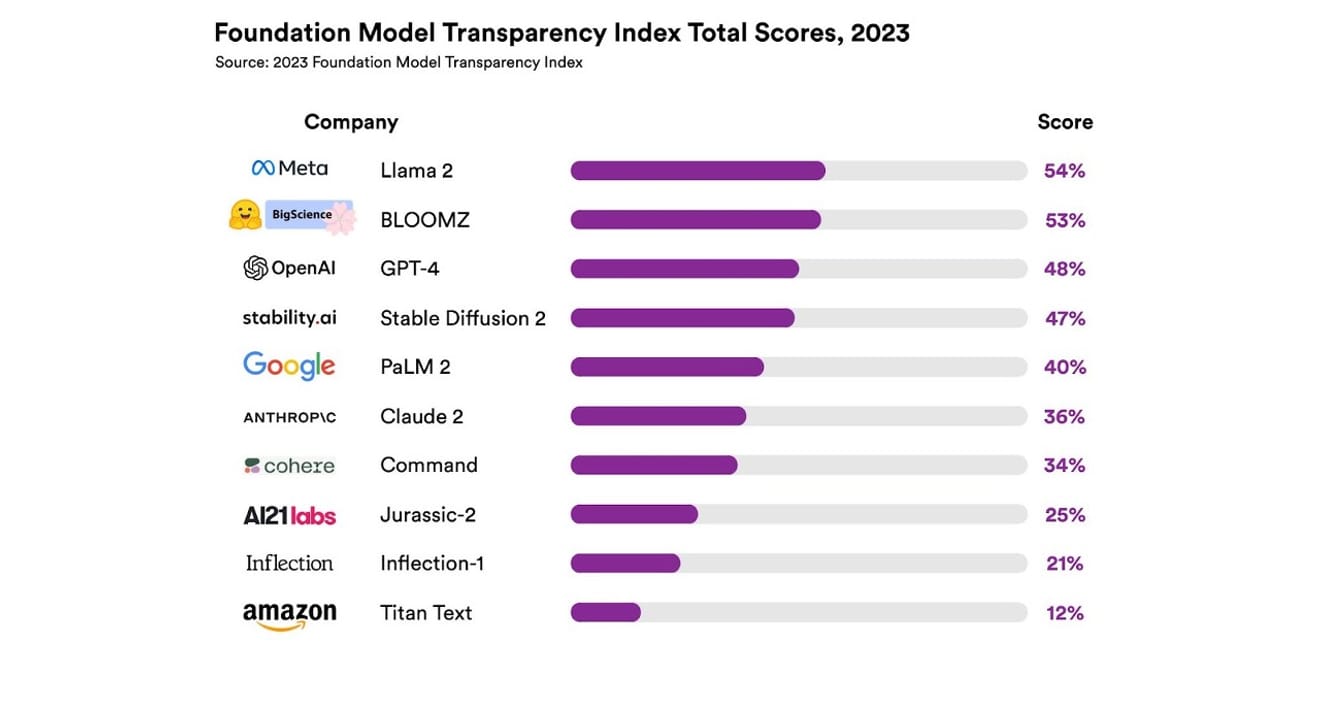
Ze onderzochten in totaal 10 verschillende AI-systemen, waarvan de meeste grote taalmodellen waren, vergelijkbaar met die welke worden gebruikt in ChatGPT en andere chatbots. Dit omvatte veelgebruikte commerciële modellen zoals GPT-4 van OpenAI, PaLM 2 van Google en Titan Text van Amazon. De openheid van de modellen werd beoordeeld op basis van 13 criteria, waaronder de mate van transparantie van de ontwikkelaars over de gegevens die werden gebruikt om de modellen te trainen (inclusief de methoden voor gegevensverzameling en -annotatie, en het gebruik van auteursrechtelijk beschermd materiaal). Ook werd onderzocht of er openheid bestond over de hardware en softwareframeworks die werden gebruikt voor het trainen en uitvoeren van de modellen, en het energieverbruik van het project.
De resultaten lieten zien dat geen enkel AI-model meer dan 54% van de transparantiemeting behaalde over alle criteria. Over het algemeen werd Titan Text van Amazon als het minst transparant beoordeeld, terwijl Llama 2 van Meta als het meest open werd bestempeld. Interessant is dat Llama 2, een prominente vertegenwoordiger van de recente tegenstelling tussen open-source en gesloten modellen, ondanks zijn open-source aard geen informatie vrijgaf over de gebruikte trainingsgegevens, de methoden voor gegevensverzameling en -curatie, etc. Dit benadrukt dat, hoewel de impact van AI op onze samenleving toeneemt, de gebrekkige transparantie in de industrie een wijdverbreid en aanhoudend fenomeen is.
Ditsuggereert dat de AI-industrie het risico loopt om een sector te worden die meer gericht is op winst dan op wetenschappelijke vooruitgang, en dat dit kan leiden tot een toekomst die wordt gedomineerd door enkele bedrijven, met alle mogelijke gevolgen van dien.

Eric Lee/Bloomberg via Getty Images
Sam Altman, CEO van OpenAI, heeft al met beleidsmakers over de hele wereld gesproken om hen te informeren over deze nieuwe en onbekende vorm van intelligentie en zijn bereidheid geuit om hen te helpen bij het concretiseren van regelgeving. Hoewel hij in principe voorstander is van een internationale instantie voor het toezicht op AI, is hij van mening dat bepaalde beperkte regels, zoals het verbieden van alle auteursrechtelijk beschermde materialen in datasets, oneerlijke obstakels kunnen vormen. Het is duidelijk dat de 'openheid' die is vervat in de naam OpenAI, is afgeweken van de radicale transparantie die aanvankelijk werd gepromoot.
Maar het is belangrijk om op te merken dat de resultaten van het Stanford-rapport laten zien dat er geen noodzaak is om elk model zo geheimzinnig te houden om concurrentievoordeel te behalen. De resultaten geven immers aan dat bijna alle bedrijven slecht presteren op dit vlak. Zo is er bijvoorbeeld geen enkel bedrijf dat statistieken verstrekt over het aantal gebruikers dat afhankelijk is van hun model, of over de geografische gebieden of marktsegmenten waar hun model wordt gebruikt.
Binnen organisaties die open source als uitgangspunt hanteren, bestaat het spreekwoord: 'veel ogen zien alles' (Linus's Law). Een groot aantal mensen helpt bij het identificeren en oplossen van problemen en het vinden van fouten die moeten worden verholpen.
Maarde praktijk van open source neigt er ook toe om de sociale status en erkenning van openheid, zowel binnen als buiten bedrijven, geleidelijk te verminderen, waardoor een onvoorwaardelijke nadruk erop weinig zinvol is. In plaats van te blijven hangen in de vraag of een model open of gesloten is, is het beter om de focus te verleggen naar hetgeleidelijk vergroten van de externe toegang tot de 'data' die ten grondslag ligt aan AI-modellen.

Voor wetenschappelijke vooruitgang is het van cruciaal belang dat de reproductieerbaarheid (Reproducibility)van specifieke onderzoeksresultaten wordt gewaarborgd. Zonder een concreet plan om transparantie te garanderen voor de belangrijkste componenten van de ontwikkeling van elk model, is de kans groot dat de sector vastloopt in een gesloten en stagnerende, monopolie-achtige situatie. En dat moet, gezien de snelheid waarmee AI-technologie zich verspreidt in alle sectoren, nu en in de toekomst als een zeer belangrijke prioriteit worden beschouwd.
Het is essentieel dat journalisten en wetenschappers de gegevens begrijpen, en voor beleidsmakers is transparantie een voorwaarde voor de beoogde beleidsinspanningen. Voor het grote publiek is transparantie eveneens van belang, aangezien ze als eindgebruikers van AI-systemen zowel dader als slachtoffer kunnen zijn van potentiële problemen met intellectuele eigendomsrechten, energieverbruik en vooroordelen. Sam Altman betoogt dat het risico op uitsterven van de mensheid als gevolg van AI tot de wereldwijde prioriteiten moet behoren, net als pandemieën en nucleaire oorlogen. Maar we mogen niet vergeten dat het voortbestaan van een samenleving die een gezonde relatie met AI onderhoudt, een voorwaarde is voordat we de gevaarlijke scenario's die hij schetst, bereiken.
*Deze tekst is de originele versie van een column die op 23 oktober 2023 in de elektronische krant 'Electronic Newspaper' is gepubliceerd.
Referenties
Reacties0