Исследование, опубликованное исследователями Стэнфордского университета 18 числа, демонстрирует, насколько глубоки и потенциально опасны секреты GPT-4 и других передовых систем ИИ.
Представление индекса прозрачности базовых моделей, Стэнфордский университет
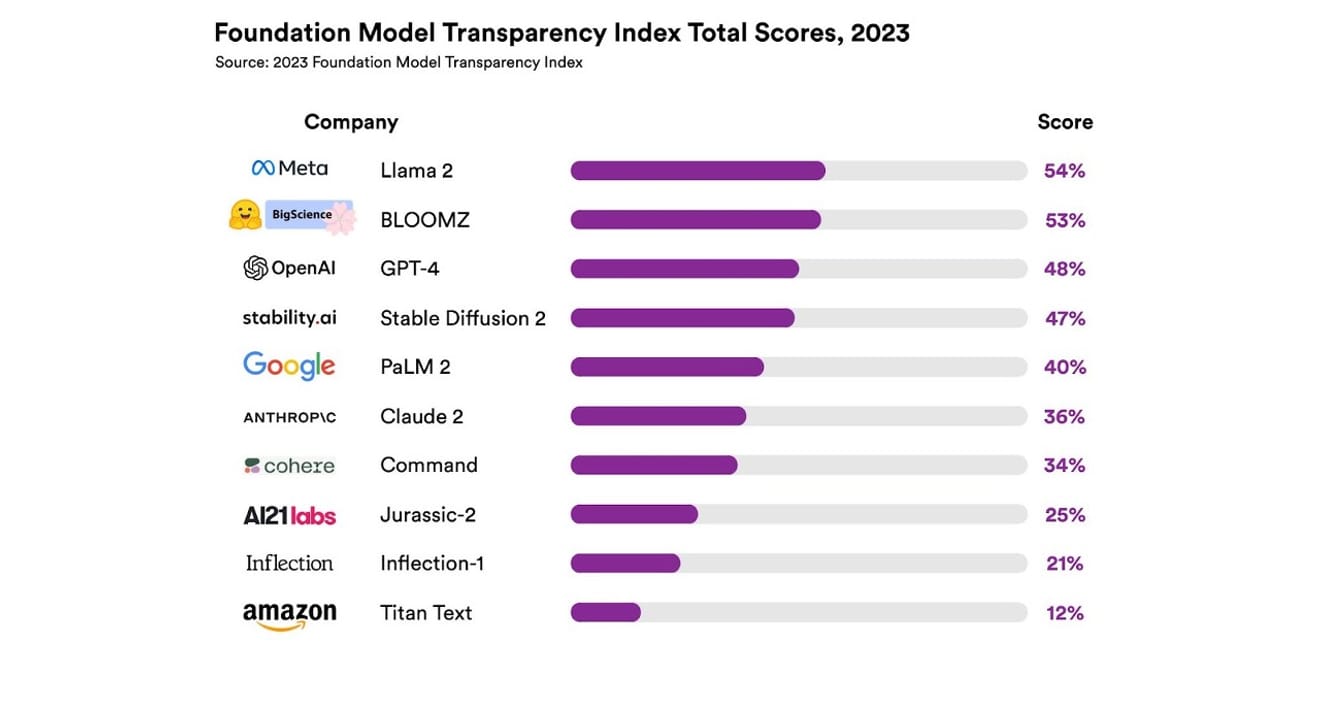
Они изучили в общей сложности 10 различных систем ИИ, большинство из которых представляли собой большие языковые модели, подобные тем, которые используются в ChatGPT и других чат-ботах. В их число вошли широко распространённые коммерческие модели, такие как GPT-4 от OpenAI, PaLM 2 от Google и Titan Text от Amazon. Исследователи оценили открытость моделей по 13 критериям, включая степень прозрачности разработчиков в отношении данных, использованных для обучения модели (включая методы сбора и аннотации данных, а также наличие материалов, защищённых авторским правом). Кроме того, они изучили, насколько открыто сообщается об используемом оборудовании и программных фреймворках для обучения и запуска модели, а также о потреблении энергии проектом.
Результаты показали, что ни одна из изученных моделей ИИ не достигла более 54% по шкале прозрачности по всем указанным критериям. В целом, Titan Text от Amazon была признана наименее прозрачной, а Llama 2 от Meta – наиболее открытой. Интересно, что Llama 2, являющаяся представителем модели с открытым исходным кодом и недавно привлекшая внимание в качестве противовеса закрытым моделям, не раскрыла данные, использованные для обучения, методы сбора и курирования данных. Это означает, что, несмотря на растущее влияние ИИ на наше общество, отраслевая непрозрачность является распространённым и постоянным явлением.
Это указывает на риск того, что отрасль ИИ вскоре может стать ориентированной не на научный прогресс, а на прибыль, что может привести к монопольному будущему под контролем определённых компаний.

Эрик Ли/Bloomberg via Getty Images
Генеральный директор OpenAI Сэм Альтман уже встречался с политиками по всему миру, активно рассказывая им об этом новом и необычном интеллекте и выражая готовность помочь в разработке соответствующих правил. Хотя он в принципе поддерживает идею международной организации по надзору за ИИ, он также считает, что некоторые ограничения, например, запрет на использование материалов, защищённых авторским правом, в наборах данных, могут стать несправедливым препятствием. Это, несомненно, свидетельствует о том, что «открытость», заложенная в название компании OpenAI, отклонилась от радикальной прозрачности, заявленной на этапе запуска.
Однако, как показывает отчёт Стэнфорда, важно отметить, что нет необходимости скрывать свои модели ради конкуренции. Результаты показывают, что практически все компании демонстрируют плохие результаты. Например, ни одна из компаний не предоставляет статистику о количестве пользователей, полагающихся на их модели, или о географическом расположении или сегментах рынка, где используются их модели.
В организациях, придерживающихся принципов открытого исходного кода, есть поговорка: «Чем больше глаз, тем меньше ошибок» (Закон Линуса). Простое число помогает выявить проблемы и найти решения, которые можно исправить.
Однако практика открытого исходного кода также имеет тенденцию постепенно снижать социальный статус и признание ценности как внутри, так и вне открытых компаний, поэтому безоговорочное его применение не имеет особого смысла. Поэтому вместо того, чтобы зацикливаться на том, является ли модель открытой или закрытой, лучше сосредоточиться на постепенном расширении внешнего доступа к «данным», лежащим в основе моделей ИИ.

Для научного прогресса важно обеспечить воспроизводимость (Reproducibility) определённых результатов исследований. Если не конкретизировать способы обеспечения прозрачности в отношении ключевых компонентов создания каждой модели, отрасль, вероятно, застрянет в замкнутом и стагнирующем монопольном положении. И это нужно помнить как весьма важный приоритет в условиях нынешнего и будущего быстрого проникновения технологий ИИ во все сферы промышленности.
Журналистам и учёным стало важно понимать данные, а для политиков прозрачность является предпосылкой для планируемых политических усилий. Для широкой общественности прозрачность также важна, поскольку в качестве конечных пользователей систем ИИ они могут быть как виновниками, так и жертвами потенциальных проблем, связанных с интеллектуальной собственностью, энергопотреблением и предвзятостью. Сэм Альтман утверждает, что риск исчезновения человечества из-за ИИ должен стать одним из глобальных приоритетов наряду с такими общественными опасностями, как пандемии и ядерная война. Однако нельзя забывать, что для достижения такого опасного положения необходимо существование нашего общества, поддерживающего здоровые отношения с развивающимся ИИ.
*Эта статья является оригиналом колонки, опубликованной в электронной газете 23 октября 2023 года.
Ссылки
Комментарии0