การวิจัยที่เผยแพร่โดยคณะนักวิจัยจากมหาวิทยาลัยสแตนฟอร์ดเมื่อวันที่ 18 ที่ผ่านมาแสดงให้เห็นว่าความลับของ GPT-4 และระบบ AI ระดับสูงอื่นๆ ลึกซึ้งเพียงใด และมีความเสี่ยงที่อาจเกิดขึ้นได้มากแค่ไหน
Introducing The Foundation Model Transparency Index, Stanford University
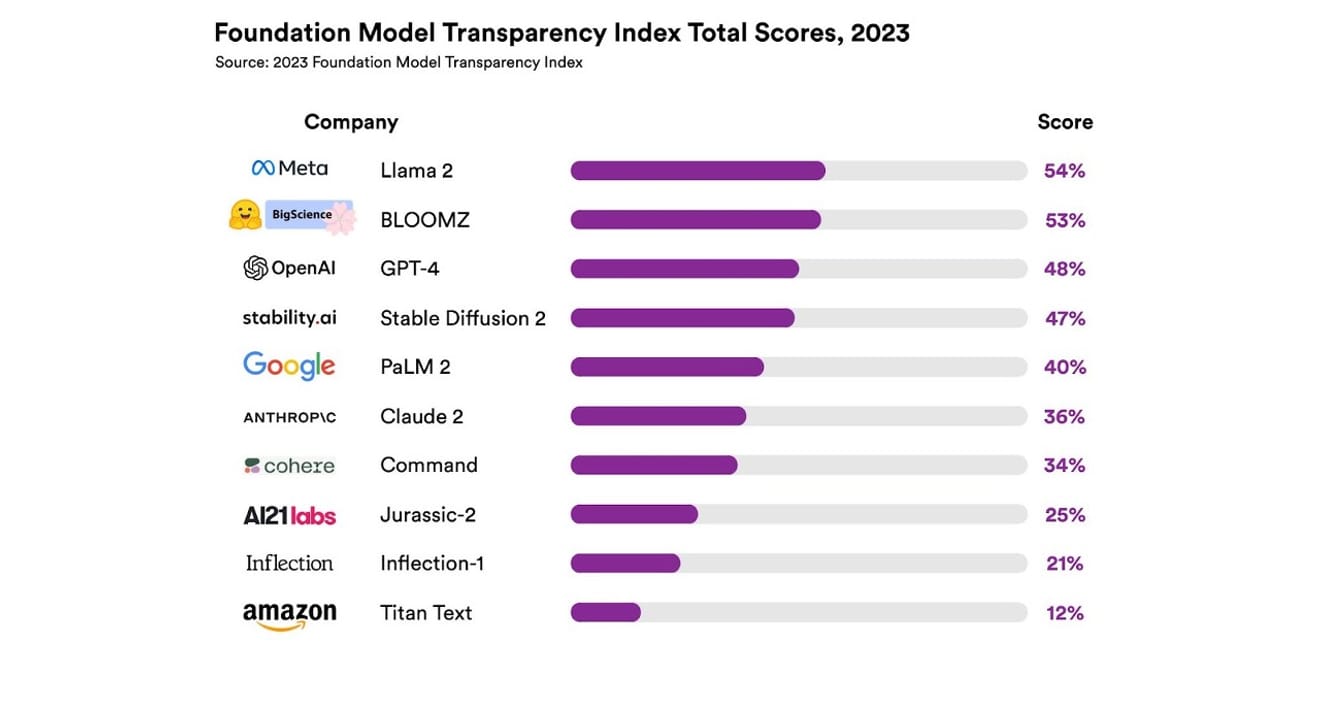
พวกเขาได้ทำการสำรวจระบบ AI ที่แตกต่างกันทั้งหมด 10 ระบบ ซึ่งส่วนใหญ่เป็นแบบจำลองภาษาขนาดใหญ่ (Large Language Model) ที่ใช้ใน ChatGPT และแชทบอทอื่นๆ เช่นเดียวกัน ซึ่งรวมถึงแบบจำลองเชิงพาณิชย์ที่ใช้กันอย่างแพร่หลาย เช่น GPT-4 ของ OpenAI, PaLM 2 ของ Google และ Titan Text ของ Amazon โดยการประเมินความโปร่งใสตามเกณฑ์ 13 ข้อ ซึ่งรวมถึงการพิจารณาว่าผู้พัฒนาเปิดเผยข้อมูลเกี่ยวกับข้อมูลที่ใช้ในการฝึกฝนแบบจำลอง (วิธีการรวบรวมและการจัดทำข้อมูล รวมถึงการใช้ข้อมูลที่มีลิขสิทธิ์หรือไม่) มากน้อยเพียงใด นอกจากนี้ยังได้ทำการสำรวจว่ามีการเปิดเผยข้อมูลเกี่ยวกับฮาร์ดแวร์ที่ใช้ในการฝึกฝนและดำเนินการแบบจำลอง โครงสร้างซอฟต์แวร์ที่ใช้ และการใช้พลังงานของโครงการหรือไม่
ผลลัพธ์ที่ได้คือ ไม่มีแบบจำลอง AI ใดที่ทำคะแนนด้านความโปร่งใสได้เกิน 54% ในทุกเกณฑ์ที่กล่าวถึง โดยภาพรวม Amazon Titan Text ได้รับการประเมินว่ามีความโปร่งใสต่ำที่สุด ขณะที่ Meta Llama 2 ได้รับการจัดอันดับว่ามีความโปร่งใสมากที่สุด ซึ่งเป็นเรื่องที่น่าสนใจที่ Llama 2 ซึ่งเป็นตัวแทนของโครงสร้างการต่อสู้ระหว่างแบบจำลองแบบเปิดและแบบปิดที่ได้รับความสนใจในช่วงไม่นานมานี้ ถึงแม้จะเป็นแบบจำลองโอเพนซอร์ส แต่ก็ไม่ได้เปิดเผยข้อมูลเกี่ยวกับข้อมูลที่ใช้ในการฝึกฝน วิธีการรวบรวมและจัดการข้อมูล เป็นต้น ซึ่งหมายความว่า แม้ว่า AI จะมีอิทธิพลต่อสังคมของเรามากขึ้นเรื่อยๆ แต่ก็ยังพบว่าอุตสาหกรรมมีความไม่โปร่งใสอย่างต่อเนื่องและแพร่หลาย
ซึ่งหมายถึงมีความเสี่ยงที่อุตสาหกรรม AI จะกลายเป็นอุตสาหกรรมที่เน้นผลกำไรมากกว่าความก้าวหน้าทางวิทยาศาสตร์ในเร็วๆ นี้ และอาจนำไปสู่การผูกขาดในอนาคตโดยบริษัทบางแห่งนั่นเอง

Eric Lee/Bloomberg via Getty Images
ซาม อัลท์แมน ซีอีโอของ OpenAI ได้พบปะกับผู้กำหนดนโยบายทั่วโลกเพื่ออธิบายเกี่ยวกับปัญญาประดิษฐ์ (AI) ที่แปลกใหม่และกำลังพัฒนาอยู่ และแสดงความเต็มใจที่จะช่วยเหลือในการกำหนดกฎระเบียบที่เกี่ยวข้อง อย่างไรก็ตาม แม้ว่าเขาจะสนับสนุนแนวคิดในการจัดตั้งองค์กรระหว่างประเทศเพื่อดูแล AI เป็นหลัก แต่เขาก็เชื่อว่ากฎบางข้อ เช่น การห้ามใช้ข้อมูลที่มีลิขสิทธิ์ในชุดข้อมูล อาจเป็นอุปสรรคที่ไม่เป็นธรรม เหตุผลที่ชื่อบริษัท OpenAI ซึ่งสะท้อนถึง 'ความเปิดกว้าง' ดูเหมือนจะเปลี่ยนแปลงไปจากความโปร่งใสที่รุนแรงที่เคยเสนอในช่วงเริ่มต้น
อย่างไรก็ตาม จากผลการศึกษาของสแตนฟอร์ดในครั้งนี้ เราจำเป็นต้องใส่ใจกับข้อเท็จจริงที่ว่า ไม่จำเป็นต้องเก็บแบบจำลองของแต่ละบริษัทไว้เป็นความลับเพื่อการแข่งขัน ผลลัพธ์ที่ได้แสดงให้เห็นถึงประสิทธิภาพที่ลดลงของเกือบทุกบริษัท ตัวอย่างเช่น ไม่มีบริษัทใดที่ให้ข้อมูลสถิติเกี่ยวกับจำนวนผู้ใช้ที่พึ่งพาแบบจำลองของตน หรือส่วนของตลาดหรือภูมิภาคที่ใช้แบบจำลองของตน
ในหมู่องค์กรที่ยึดถือหลักการโอเพนซอร์ส มีสุภาษิตที่ว่า 'ยิ่งมีคนมองเห็นมากเท่าไหร่ ก็ยิ่งพบข้อผิดพลาดมากขึ้นเท่านั้น' (กฎของลินุส) ตัวเลขที่ดิบๆ สามารถช่วยในการค้นหาปัญหาและแก้ไขปัญหาที่สามารถแก้ไขได้
แต่แนวทางการปฏิบัติแบบโอเพนซอร์สยังมีแนวโน้มที่จะทำให้สถานะทางสังคมและการยอมรับคุณค่าทั้งภายในและภายนอกองค์กรที่เปิดเผยข้อมูลลดลงดังนั้น การเน้นย้ำอย่างไม่มีเงื่อนไขจึงไม่ค่อยมีความหมายมากนัก ด้วยเหตุนี้ แทนที่จะยึดติดกับกรอบการคิดเกี่ยวกับแบบจำลองแบบเปิดและแบบปิด เราควรเน้นไปที่การขยายการเข้าถึง 'ข้อมูล' ที่เป็นพื้นฐานของแบบจำลอง AI ให้กว้างขึ้นทีละน้อยซึ่งอาจเป็นทางเลือกที่ดีกว่า

การพัฒนาทางวิทยาศาสตร์นั้นการตรวจสอบซ้ำ (Reproducibility) ว่าผลลัพธ์การวิจัยบางอย่างจะปรากฏขึ้นอีกหรือไม่เป็นสิ่งสำคัญหากไม่มีการกำหนดวิธีการที่ชัดเจนเพื่อให้แน่ใจว่ามีความโปร่งใสในองค์ประกอบหลักของการสร้างแบบจำลองแต่ละแบบ ในที่สุดอุตสาหกรรมก็อาจติดอยู่ในสถานการณ์ที่ปิดกั้นและหยุดนิ่ง ซึ่งเป็นสถานการณ์ที่เกิดจากการผูกขาด และนี่เป็นสิ่งที่ควรได้รับการพิจารณาอย่างจริงจังในฐานะลำดับความสำคัญที่สำคัญในปัจจุบันและอนาคต เนื่องจากเทคโนโลยี AI กำลังแพร่หลายในทุกอุตสาหกรรมอย่างรวดเร็ว
สำหรับนักข่าวและนักวิทยาศาสตร์ การทำความเข้าใจข้อมูลเป็นสิ่งสำคัญ และสำหรับผู้กำหนดนโยบาย ความโปร่งใสเป็นเงื่อนไขเบื้องต้นสำหรับความพยายามในด้านนโยบายที่วางแผนไว้ สำหรับประชาชนทั่วไป ความโปร่งใสก็มีความสำคัญเช่นกัน เนื่องจากในฐานะผู้ใช้ AI พวกเขาอาจเป็นผู้กระทำผิดหรือผู้เสียหายจากปัญหาระดับปัญญาประดิษฐ์ (AI) ที่เกี่ยวข้องกับทรัพย์สินทางปัญญา การใช้พลังงาน และอคติ ซาม อัลท์แมนกล่าวว่าความเสี่ยงจากการสูญพันธุ์ของมนุษย์จาก AI ควรเป็นลำดับความสำคัญระดับโลก เช่นเดียวกับภัยคุกคามในระดับสังคมอื่นๆ เช่น โรคระบาดหรือสงครามนิวเคลียร์ อย่างไรก็ตาม เราไม่ควรลืมว่าการดำรงอยู่ของสังคมของเราในการรักษาความสัมพันธ์ที่ดีกับ AI ที่กำลังพัฒนาขึ้นนั้นเป็นสิ่งที่ต้องมีก่อนที่จะเกิดสถานการณ์อันตรายที่เขากล่าวถึง
*บทความนี้เป็นต้นฉบับของคอลัมน์ที่ตีพิมพ์ในหนังสือพิมพ์อิเล็กทรอนิกส์เมื่อวันที่ 23 ตุลาคม 2566*
เอกสารอ้างอิง
ความคิดเห็น0