Geçtiğimiz 18'inde Stanford Üniversitesi araştırmacılarının yayınladığı çalışma, GPT-4 ve diğer son teknoloji AI sistemlerinin sırlarının ne kadar derin ve potansiyel olarak tehlikeli olduğunu gösteriyor.
Stanford Üniversitesi'nden Temel Model Şeffaflık Endeksi'nin Tanıtımı
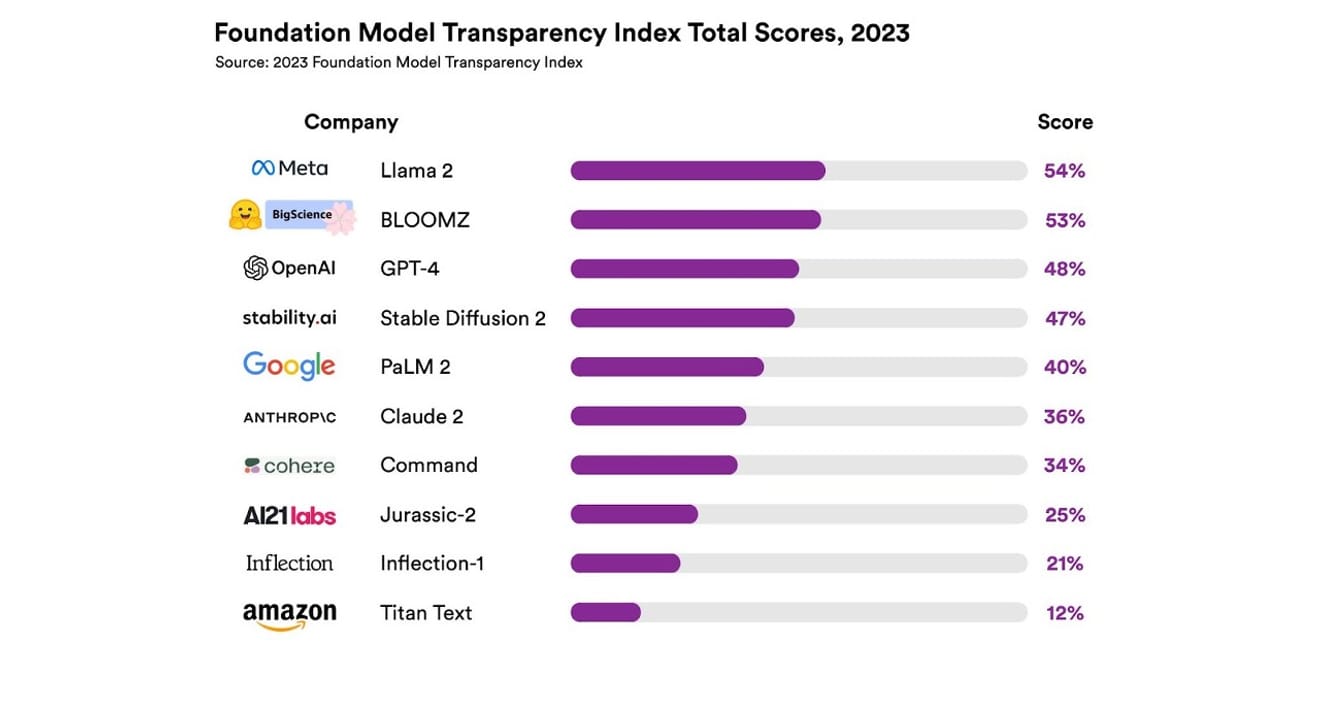
Çalışmada toplam 10 farklı AI sistemi incelendi ve bunların çoğu ChatGPT ve diğer sohbet robotlarında kullanılan büyük dil modelleri (LLM) idi. Bunlar arasında OpenAI'nin GPT-4'ü, Google'ın PaLM 2'si, Amazon'un Titan Text'i gibi yaygın olarak kullanılan ticari modeller de yer alıyordu. Araştırmacılar, 13 farklı kriter kullanarak bu modellerin açıklık derecesini değerlendirdi. Bu kriterler arasında geliştiricilerin model eğitiminde kullanılan verilere (veri toplama ve etiketleme yöntemleri, telif hakkıyla korunan materyallerin dahil edilip edilmediği gibi) ne kadar şeffaflık sağladığı da yer alıyordu. Ayrıca, modelin eğitilmesi ve çalıştırılması için kullanılan donanım, kullanılan yazılım çerçevesi ve projenin enerji tüketimi gibi konularda ne kadar bilgi paylaşıldığı da incelendi.
Sonuçlar, tüm kriterler genelinde açıklık ölçeğinde %54'ün üzerinde puan alan bir AI modelinin olmadığını ortaya koydu. Genel olarak, Amazon'un Titan Text'i en düşük şeffaflığa sahip model olarak değerlendirilirken, Meta'nın Llama 2'si en açık model olarak seçildi. İlginç bir şekilde, son zamanlarda dikkat çeken açık ve kapalı model ayrışmasının temsilcilerinden biri olan Llama 2, açık kaynaklı bir model olmasına rağmen, eğitimde kullanılan veriler, veri toplama ve düzenleme yöntemleri gibi konuları açıklamadı. Yani, AI'nın toplumumuz üzerindeki etkisi artmaya devam ederken, sektördeki ilgili şeffaflık eksikliği yaygın ve sürekli bir durum olarak gözlemleniyor.
Bu durum,AI sektörünün yakında bilimsel gelişmeden ziyade kâr odaklı bir alan haline gelme riskinin ve belirli şirketlerin yönlendirdiği tekelci bir geleceğe doğru evrilme olasılığının olduğunu gösteriyor .

Eric Lee/Bloomberg via Getty Images
OpenAI CEO'su Sam Altman zaten dünyanın dört bir yanındaki politika yapıcılarla bir araya gelerek, onlara bu yabancı ve yeni zekâ hakkında bilgi vermeye ve ilgili düzenlemelerin somutlaştırılmasına yardımcı olmaya istekli olduğunu açıkça belirtti. Ancak, prensip olarak AI'yı denetleyen uluslararası bir kuruluş fikrini desteklerken, veri kümelerindeki tüm telif hakkıyla korunan materyalleri yasaklamak gibi bazı sınırlı kuralların haksız bir engel oluşturabileceğini düşünüyor. OpenAI şirket adında yer alan 'açıklık' kavramının, kuruluş aşamasında sunulan radikal şeffaflıktan uzaklaştığının açıkça görüldüğü bir durum.
Ancak bu Stanford raporunun sonuçlarında, rekabet için modellerini bu kadar gizli tutmanın gerekli olmadığına da dikkat çekilmesi gerekiyor. Sonuçlar, hemen hemen tüm şirketlerin zayıf yönlerini gösteren bir gösterge niteliğinde çünkü örneğin, hiçbir şirket kendi modellerine ne kadar kullanıcının güvendiğini veya modellerini kullanan coğrafi bölgeler veya pazar segmentleri hakkında istatistikler sunmuyor.
Açık kaynaklı ilkeleri benimseyen kuruluşlar arasında 'Çok sayıda göz her hatayı ortaya çıkarır' atasözü vardır (Linus's Law). Ham sayılar, sorunları çözmeye ve düzeltilebilecek sorunları bulmaya yardımcı olur.
Ancakaçık kaynak uygulamaları, giderek, kamu şirketleri içinde ve dışında toplumsal konum ve değer tanıma kaybına yol açma eğilimindedir , bu nedenle koşulsuz vurgulama pek anlamlı değildir. Bu nedenle, modelin açık veya kapalı olup olmamasına dair çerçevede kalmak yerine, güçlü bir AI modelinin temelini oluşturan 'verilere' dış erişimi kademeli olarak genişletmek üzerine odaklanmak daha iyi bir seçenek olabilir.

Bilimsel gelişmede, belirli bir araştırma sonucunun tekrar edilip edilmediğini doğrulayan tekrarlanabilirlik (Yeniden Üretilebilirlik) sağlamak önemlidir. Bu sayede, her model oluşturmanın temel bileşenlerine yönelik şeffaflık sağlayan bir yol belirlenmezse, sektör sonunda kapalı ve durgun bir tekelci duruma düşme olasılığı yüksektir. Ve bunun, AI teknolojisinin hızla tüm sektörlere nüfuz ettiği şu anda ve gelecekte oldukça önemli bir öncelik olarak değerlendirilmesi gerektiğini hatırlamalıyız.
Gazeteciler ve bilim insanları için verileri anlamak önemli hale geldi ve politika yapıcılar için şeffaflık, planlanmış politik çabaların ön koşuludur. Toplum için de şeffaflık önemlidir çünkü AI sistemlerinin nihai kullanıcısı olarak, fikri mülkiyet hakları, enerji kullanımı, önyargılarla ilgili potansiyel sorunların faili veya mağduru olabilirler. Sam Altman, AI kaynaklı insan neslinin tükenme riskinin, salgın hastalıklar veya nükleer savaş gibi toplumsal ölçekte riskler arasında küresel bir öncelik haline gelmesi gerektiğini savunuyor. Ancak, onun belirttiği tehlikeli duruma ulaşana kadar, gelişen AI ile sağlıklı bir ilişki sürdüren toplumumuzun varlığının ön koşul olduğunu unutmamalıyız.
*Bu yazı, 23 Ekim 2023 tarihli Elektronik Haber gazetesinde yayınlanan imzalı köşe yazısının orijinalidir.
Referanslar
Yorumlar0