去年18日,史丹佛大學研究團隊發布的研究顯示,GPT-4和其他最先進的AI系統的秘密有多麼深奧,以及潛在的危險性。
斯坦福大學推出基礎模型透明度指數 (Introducing The Foundation Model Transparency Index, Stanford University)
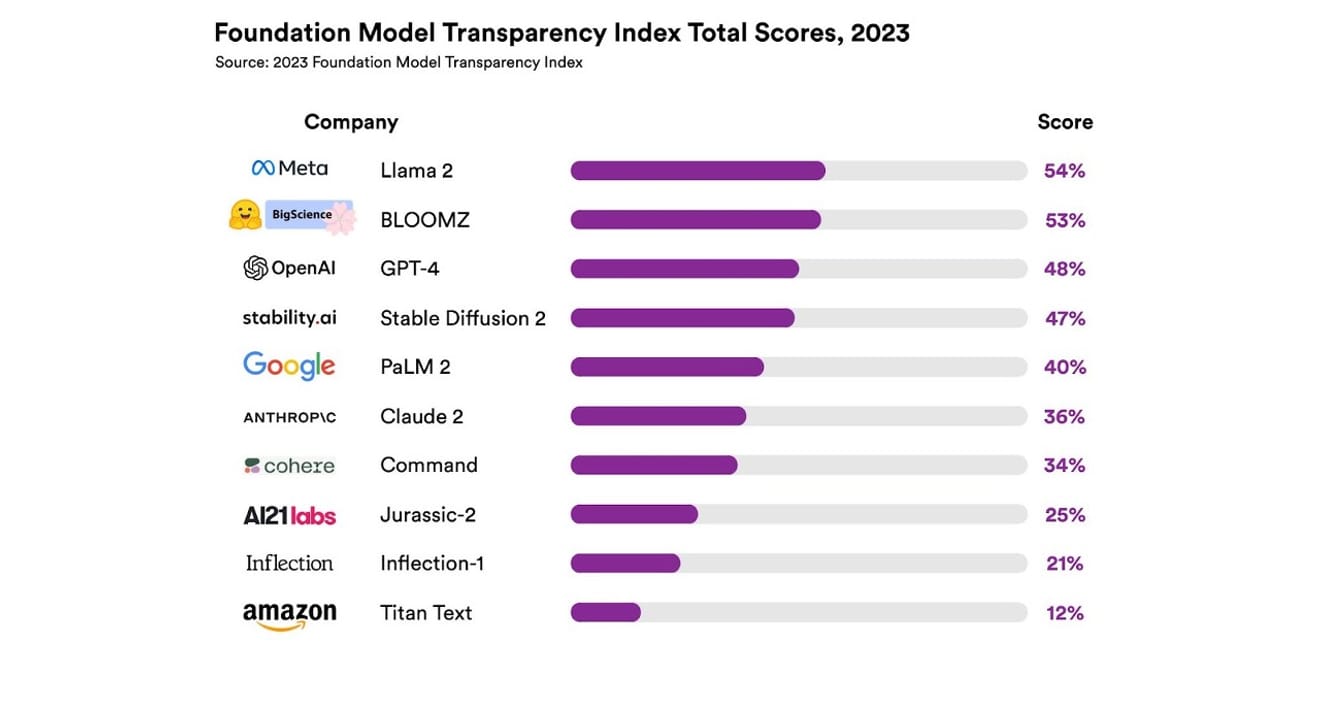
他們總共調查了10個不同的AI系統,大多數都是像ChatGPT和其他聊天機器人所使用的,大型語言模型。其中包括廣泛使用的商業模型,例如OpenAI的GPT-4、Google的PaLM 2和Amazon的Titan Text,並根據13項標準評估了這些模型的開放性,包括開發人員在模型訓練數據方面公開的透明度(包括數據收集和標註方法、是否包含受版權保護的材料等)。此外,他們還調查了這些模型在訓練和運行時所使用的硬件、軟件框架以及專案的能源消耗是否公開。
結果顯示,沒有任何一個AI模型在透明度指標上超過54%。整體而言,Amazon的Titan Text被評估為透明度最低的模型,而Meta的Llama 2則被評估為最開放的模型。有趣的是,最近備受關注的開放式和封閉式模型對立結構的代表性模型Llama 2,儘管是開源模型,但卻沒有公開其訓練數據、數據收集和策展方法等。也就是說,儘管AI對我們社會的影響力越來越大,但業界相關的不透明性卻是一種普遍且持續存在的現象。
這意味著AI產業很快就會面臨成為以營利為導向的領域,而非科學進步的領域的風險,並且可能導致特定企業主導的壟斷性未來。

Eric Lee/彭博社/蓋蒂圖片社 (Eric Lee/Bloomberg via Getty Images)
OpenAI的執行長山姆·阿爾特曼已經與全球各地的決策者會面,積極向他們說明這種陌生而新穎的智能,並公開表示願意協助制定相關法規。然而,他原則上支持建立監督AI的國際組織的想法,但也認為某些限制性規則,例如禁止數據集中所有受版權保護的材料,可能會成為不公平的障礙。OpenAI這個公司名稱中所蘊含的「開放性」,顯然已經偏離了其成立之初所提出的激進透明性。
但是,正如史丹佛報告的結果所揭示的那樣,我們也需要注意,為了競爭而將各自的模型保密並沒有必要。因為該結果也是幾乎所有企業都表現不佳的指標。例如,據說沒有任何一家公司提供其模型有多少用戶依賴、使用其模型的區域或市場部分等統計數據。
在以開源為原則的組織中,有一句諺語:「人多眼雜,蟲害無所遁形。」(Linus's law)原始的數字有助於發現需要解決和修復的問題。
但是開源慣例也逐漸導致公開企業在社會地位和價值認可方面失去內外部地位,因此毫無保留地強調開源並沒有太大意義。因此,與其拘泥於模型是開放式還是封閉式的框架,不如將討論重點放在逐步擴大外部訪問AI模型基礎的「數據」上,這可能是更好的選擇。

科學進步需要確保特定研究結果的可重複性。可重複性(Reproducibility)的確保至關重要。藉此,可以具體化確保模型生成主要組成部分透明度的方案,否則,產業最終很可能會停滯在封閉且停滯的壟斷狀態。並且,我們必須記住,在AI技術快速滲透到各行各業的當前和未來情況下,這是一個相當重要的優先事項。
對於新聞工作者和科學家來說,理解數據變得越來越重要,而對於決策者來說,透明度是預期政策努力的前提條件。對於公眾來說,透明度也很重要,因為作為AI系統的最終用戶,他們可能會成為與智慧財產權、能源使用量和偏見相關的潛在問題的加害者或受害者。山姆·阿爾特曼主張,AI帶來的滅絕風險應成為全球優先事項,與傳染病或核戰爭等社會規模的風險同等重要。然而,我們不應忘記,在達到他所提到的危險境地之前,我們社會維持與不斷發展的AI之間的健康關係是前提條件。
*本文是2023年10月23日刊登於電子新聞的署名專欄的原文。
參考資料
重振Mozilla的開放性:一種混合方法研究方法
评论0