18 तारीख को स्टैनफोर्ड विश्वविद्यालय के शोधकर्ताओं द्वारा प्रकाशित शोध से पता चलता है कि GPT-4 और अन्य अत्याधुनिक AI सिस्टम के रहस्य कितने गहरे और संभावित रूप से खतरनाक हैं।
परिचय द फाउंडेशन मॉडल ट्रांसपेरेंसी इंडेक्स, स्टैनफोर्ड यूनिवर्सिटी (Introducing The Foundation Model Transparency Index, Stanford University)
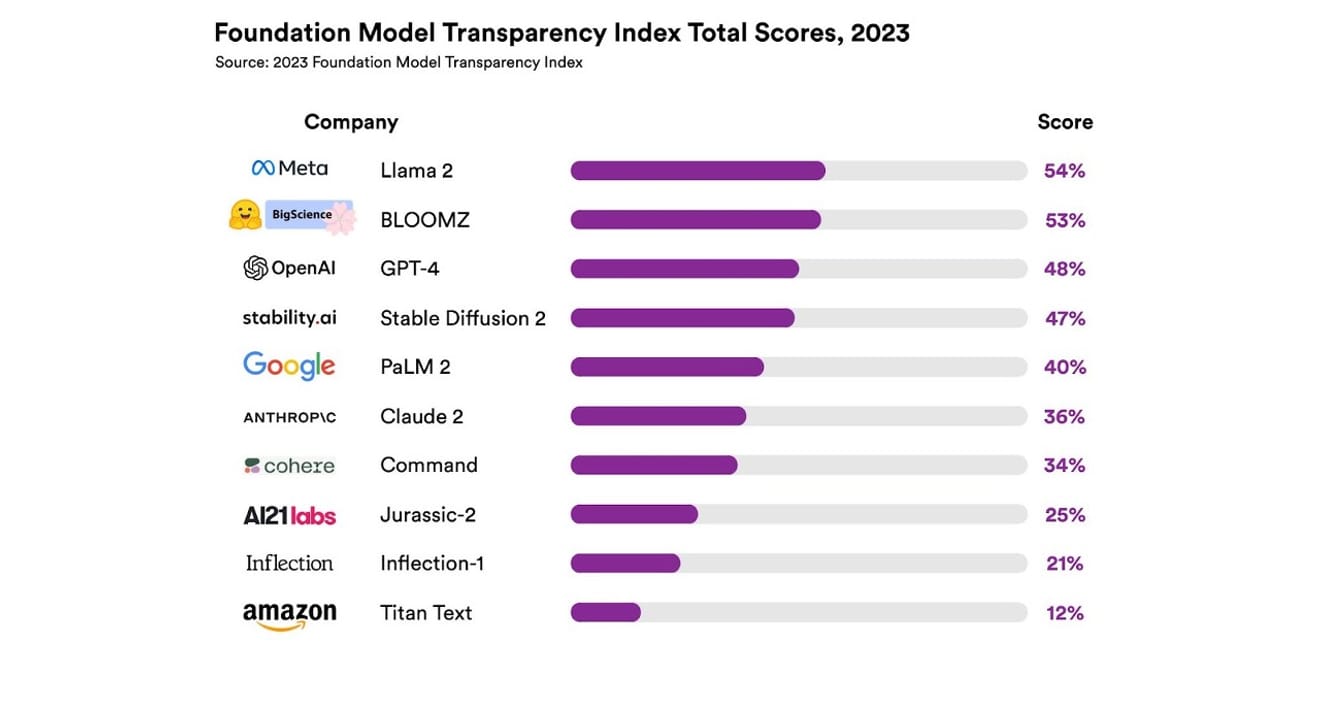
उन्होंने कुल 10 अलग-अलग AI सिस्टम का अध्ययन किया, जिनमें से अधिकांश बड़े भाषा मॉडल थे, जैसे कि ChatGPT और अन्य चैटबॉट में उपयोग किए जाते हैं। इसमें OpenAI का GPT-4, Google का PaLM 2, Amazon का Titan Text जैसे व्यापक रूप से उपयोग किए जाने वाले वाणिज्यिक मॉडल शामिल हैं, और उन्होंने 13 मानदंडों के आधार पर खुलेपन का मूल्यांकन किया, जिसमें यह शामिल था कि डेवलपर्स ने मॉडल को प्रशिक्षित करने के लिए उपयोग किए गए डेटा के बारे में कितना पारदर्शी रूप से खुलासा किया है (डेटा संग्रह और एनोटेशन विधियां, कॉपीराइट सामग्री की उपस्थिति, आदि)। उन्होंने यह भी जांच की कि मॉडल को प्रशिक्षित करने और चलाने के लिए उपयोग किए जाने वाले हार्डवेयर, उपयोग किए जाने वाले सॉफ़्टवेयर फ़्रेमवर्क और परियोजना की ऊर्जा खपत के बारे में खुलासा किया गया है या नहीं।
परिणाम यह था कि किसी भी AI मॉडल ने पारदर्शिता पैमाने पर 54% से अधिक अंक हासिल नहीं किए, जो कि सभी मानदंडों में था। कुल मिलाकर, Amazon का Titan Text को सबसे कम पारदर्शी माना गया, जबकि Meta का Llama 2 को सबसे खुला पाया गया। दिलचस्प बात यह है कि हाल ही में ध्यान आकर्षित करने वाले ओपन-सोर्स और क्लोज्ड-सोर्स मॉडल विवाद के प्रतिनिधि, Llama 2, एक ओपन-सोर्स मॉडल होने के बावजूद, प्रशिक्षण डेटा, डेटा संग्रह और क्यूरेशन विधियों का खुलासा नहीं करता है। दूसरे शब्दों में, भले ही AI का हमारे समाज पर प्रभाव बढ़ रहा है, उद्योग में संबंधित अपारदर्शिता एक व्यापक और निरंतर घटना है।
इसका अर्थ है कि AI उद्योग के वैज्ञानिक प्रगति के बजाय लाभ-केंद्रित क्षेत्र बनने का जोखिम है, और यह एक विशिष्ट कंपनी के नेतृत्व वाले एकाधिकारवादी भविष्य की ओर ले जा सकता है।

एरिक ली/ब्लूमबर्ग गेट्टी इमेजेज के माध्यम से (Eric Lee/Bloomberg via Getty Images)
OpenAI के सीईओ सैम ऑल्टमैन पहले ही दुनिया भर के नीति निर्माताओं से मुलाकात कर चुके हैं, उन्हें इस अपरिचित और नई बुद्धिमत्ता के बारे में सक्रिय रूप से समझा रहे हैं और संबंधित नियमों को ठोस बनाने में मदद करने की इच्छा व्यक्त कर रहे हैं। हालांकि, वे सिद्धांत रूप में AI को विनियमित करने के लिए एक अंतर्राष्ट्रीय संगठन के विचार का समर्थन करते हैं, लेकिन वे यह भी मानते हैं कि कुछ सीमित नियम, जैसे कि डेटासेट से सभी कॉपीराइट सामग्री को प्रतिबंधित करना, अनुचित बाधाएं पैदा कर सकते हैं। OpenAI कंपनी के नाम में निहित 'खुलापन' स्पष्ट रूप से उस कट्टरपंथी पारदर्शिता से भिन्न है जो इसकी स्थापना के समय प्रस्तुत की गई थी।
लेकिन स्टैनफोर्ड रिपोर्ट के निष्कर्षों पर ध्यान देने योग्य है कि प्रतिस्पर्धा के लिए अपने मॉडल को इतने गुप्त रखने की आवश्यकता नहीं है। क्योंकि परिणाम लगभग सभी कंपनियों के खराब प्रदर्शन का संकेतक भी है। उदाहरण के लिए, कोई भी कंपनी यह आंकड़ा प्रदान नहीं करती है कि उसके मॉडल पर कितने उपयोगकर्ता निर्भर हैं, या वे कौन से क्षेत्र या बाजार खंड हैं जहां उनके मॉडल का उपयोग किया जा रहा है।
ओपन-सोर्स सिद्धांतों पर आधारित संगठनों में, एक कहावत है, 'जहां कई आँखें हैं, वहाँ सभी कीड़े दिखाई देते हैं' (लिनस का नियम)। कच्ची संख्याएँ समस्याओं को हल करने और सुधारने के लिए समस्याओं की पहचान करने में मदद करती हैं।
लेकिन ओपन-सोर्स प्रथाओं की प्रवृत्ति धीरे-धीरे सार्वजनिक कंपनियों के भीतर और बाहर सामाजिक स्थिति और मूल्य मान्यता को कम करने की हैइसलिए बिना शर्त जोर देने का कोई बड़ा मतलब नहीं है। इसलिए, मॉडल के खुले या बंद होने के ढाँचे में बने रहने के बजाय, मजबूत AI मॉडल के आधार 'डेटा' तक बाहरी पहुंच को धीरे-धीरे व्यापक बनानाचर्चा के केंद्र में रखना बेहतर विकल्प हो सकता है।

वैज्ञानिक प्रगति के लिए यह सुनिश्चित करना महत्वपूर्ण है कि कुछ शोध परिणाम दोहराए जा सकें, यानी पुनरुत्पादन क्षमता (पुनरुत्पादन क्षमता) सुनिश्चित करना। इसके माध्यम से, प्रत्येक मॉडल निर्माण के प्रमुख घटकों के लिए पारदर्शिता सुनिश्चित करने के तरीके को ठोस बनाया जाना चाहिए, अन्यथा उद्योग बंद और स्थिर एकाधिकारवादी स्थिति में रहने की संभावना है। और यह एक ऐसी स्थिति है जिसे वर्तमान में और भविष्य में विभिन्न उद्योगों में AI प्रौद्योगिकी के तेजी से प्रसार के संदर्भ में एक उच्च प्राथमिकता के रूप में माना जाना चाहिए।
पत्रकारों और वैज्ञानिकों के लिए डेटा को समझना महत्वपूर्ण हो गया है, और नीति निर्माताओं के लिए पारदर्शिता नियोजित नीतिगत प्रयासों की एक शर्त है। जनता के लिए भी, पारदर्शिता AI सिस्टम के अंतिम उपयोगकर्ता के रूप में महत्वपूर्ण है, क्योंकि वे बौद्धिक संपदा अधिकारों, ऊर्जा खपत और पूर्वाग्रह से संबंधित संभावित मुद्दों में अपराधी या पीड़ित हो सकते हैं। सैम ऑल्टमैन का तर्क है कि AI के कारण मानव विनाश का खतरा वैश्विक प्राथमिकता बनना चाहिए, जैसे कि महामारी या परमाणु युद्ध जैसे सामाजिक पैमाने पर खतरे। हालांकि, हमें यह नहीं भूलना चाहिए कि इस खतरनाक स्थिति में पहुँचने से पहले, AI के साथ एक स्वस्थ संबंध बनाए रखने वाले हमारे समाज का अस्तित्व एक शर्त है।
*यह लेख 23 अक्टूबर, 2023 को इलेक्ट्रॉनिक न्यूज़पेपर में प्रकाशित एक हस्ताक्षरित स्तंभ का मूल संस्करण है।
संदर्भ
टिप्पणियाँ0