Uma pesquisa publicada em 18 de setembro por pesquisadores da Universidade Stanford revela o quão profundo e potencialmente perigoso é o segredo por trás do GPT-4 e de outros sistemas de IA de ponta.
Apresentando o Índice de Transparência de Modelos Fundamentais, Universidade de Stanford
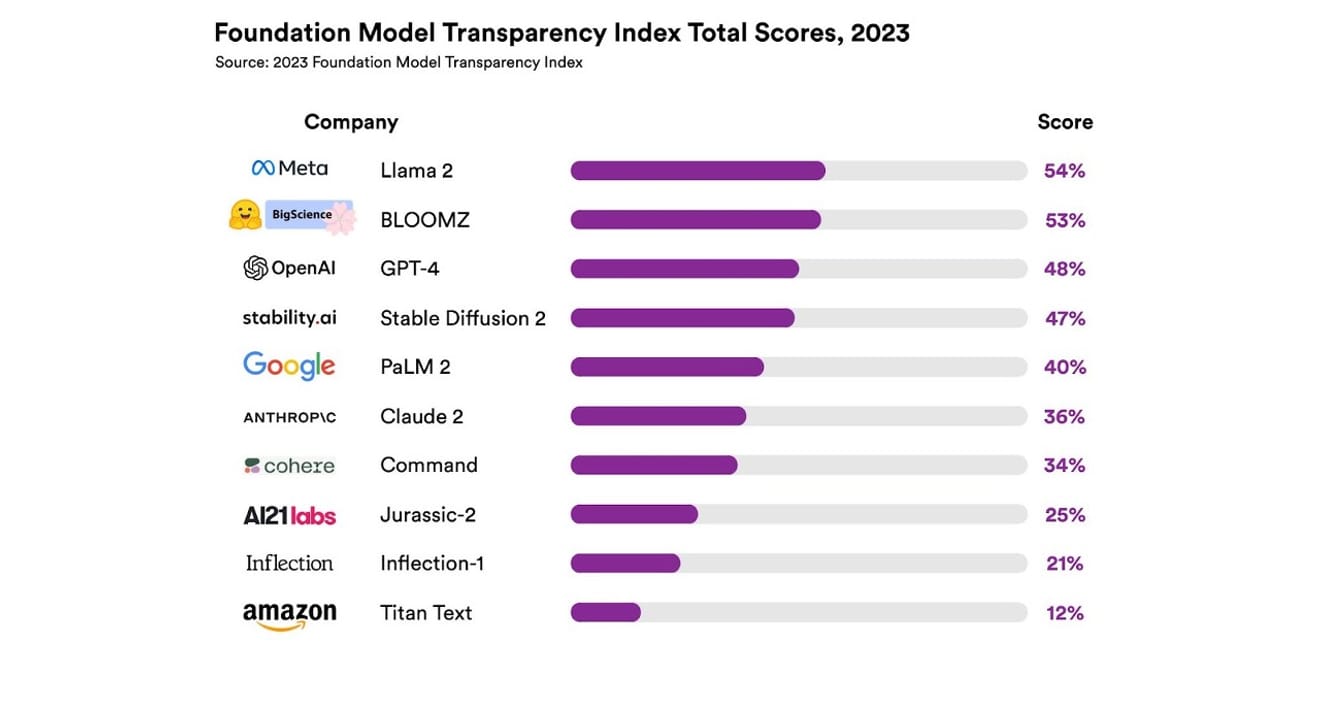
Eles examinaram um total de 10 sistemas de IA diferentes, a maioria dos quais eram modelos de linguagem de grande escala (LLMs), como os usados no ChatGPT e em outros chatbots. Isso inclui modelos comerciais amplamente utilizados, como o GPT-4 da OpenAI, o PaLM 2 do Google e o Titan Text da Amazon. Os pesquisadores avaliaram a abertura desses modelos com base em 13 critérios, incluindo a transparência com que os desenvolvedores revelaram os dados usados para treinar os modelos (incluindo métodos de coleta e anotação de dados e se materiais protegidos por direitos autorais foram incluídos). Eles também investigaram se havia divulgação sobre o hardware usado para treinar e executar os modelos, as estruturas de software empregadas e o consumo de energia do projeto.
Os resultados mostraram que nenhum modelo de IA atingiu mais de 54% na escala de transparência em todos os critérios mencionados. No geral, o Titan Text da Amazon foi classificado como o menos transparente, enquanto o Llama 2 do Meta foi considerado o mais aberto. O interessante é que o Llama 2, um modelo open source (de código aberto) que representa a oposição entre modelos abertos e fechados que tem ganhado destaque recentemente, não divulgou os dados usados para treinamento, os métodos de coleta e curadoria de dados, etc. Em outras palavras, apesar da crescente influência da IA na sociedade, a falta de transparência no setor é um fenômeno generalizado e persistente.
Issosignifica que a indústria de IA corre o risco de se tornar uma área focada em lucros em vez de avanços científicos, o que pode levar a um futuro monopolizado e controlado por empresas específicas.

Eric Lee/Bloomberg via Getty Images
Sam Altman, CEO da OpenAI, já se encontrou com formuladores de políticas em todo o mundo para explicar essa inteligência nova e incomum a eles e oferecer sua ajuda na criação de regulamentações específicas. Embora ele apoie a ideia de um órgão internacional para supervisionar a IA em princípio, ele também acredita que algumas regras limitadas, como a proibição de todos os materiais protegidos por direitos autorais nos conjuntos de dados, podem ser obstáculos injustos. É claro que a 'abertura' no nome da empresa OpenAI se desviou da transparência radical que ela propôs inicialmente.
No entanto, os resultados do relatório de Stanford também destacam que não há necessidade de manter os modelos tão secretos para fins de competição. Isso ocorre porque os resultados representam um indicador de desempenho ruim para quase todas as empresas. Por exemplo, nenhuma empresa fornece estatísticas sobre quantos usuários dependem de seus modelos ou sobre a região ou segmento de mercado em que seus modelos são usados.
Nas organizações que seguem os princípios do open source, há um provérbio que diz: 'Com muitos olhos, todos os erros são descobertos' (Lei de Linus). Um grande número de pessoas ajuda a identificar e resolver problemas e a corrigir defeitos.
No entanto,as práticas do open source também tendem a diminuir gradualmente o status social e o reconhecimento de valor dentro e fora das empresas que se abrem, por isso enfatizá-las incondicionalmente não é muito significativo. Em vez de ficar preso na estrutura de se os modelos são abertos ou fechados, seria melhor focar a discussão emampliar gradualmente o acesso externo aos 'dados' que servem de base para os modelos de IA.

Para o avanço científico, é importante garantir areprodutibilidade (Reproducibility) dos resultados de pesquisa específicos. Se não desenvolvermos métodos específicos para garantir a transparência em relação aos principais componentes da criação de cada modelo, a indústria provavelmente ficará presa em uma situação monopolizada e estagnada. E é importante lembrar que isso deve ser considerado uma prioridade alta no contexto atual, em que a tecnologia de IA está se integrando rapidamente a todos os setores da indústria e continuará a fazê-lo no futuro.
É essencial que jornalistas e cientistas compreendam os dados, e para os formuladores de políticas, a transparência é uma condição prévia para os esforços políticos planejados. Para o público em geral, a transparência também é importante porque, como usuários finais dos sistemas de IA, eles podem ser vítimas ou perpetradores de potenciais problemas relacionados a propriedade intelectual, uso de energia e viés. Sam Altman argumenta que o risco de extinção da humanidade causado pela IA deve ser uma prioridade global, semelhante a pandemias ou guerra nuclear. No entanto, não devemos esquecer que, para chegar a esse cenário de risco, a sobrevivência da nossa sociedade, mantendo um relacionamento saudável com a IA em desenvolvimento, é uma condição prévia essencial.
*Este artigo é a versão original de um artigo publicado no jornal eletrônico 'Electronic Newspaper' em 23 de outubro de 2023.
Referências
Comentários0