Penelitian yang dirilis oleh para peneliti Universitas Stanford pada tanggal 18 lalu menunjukkan seberapa dalam dan berpotensi bahayanya rahasia yang tersimpan di dalam GPT-4 dan sistem AI canggih lainnya.
Mengenalkan Indeks Transparansi Model Fondasi, Universitas Stanford
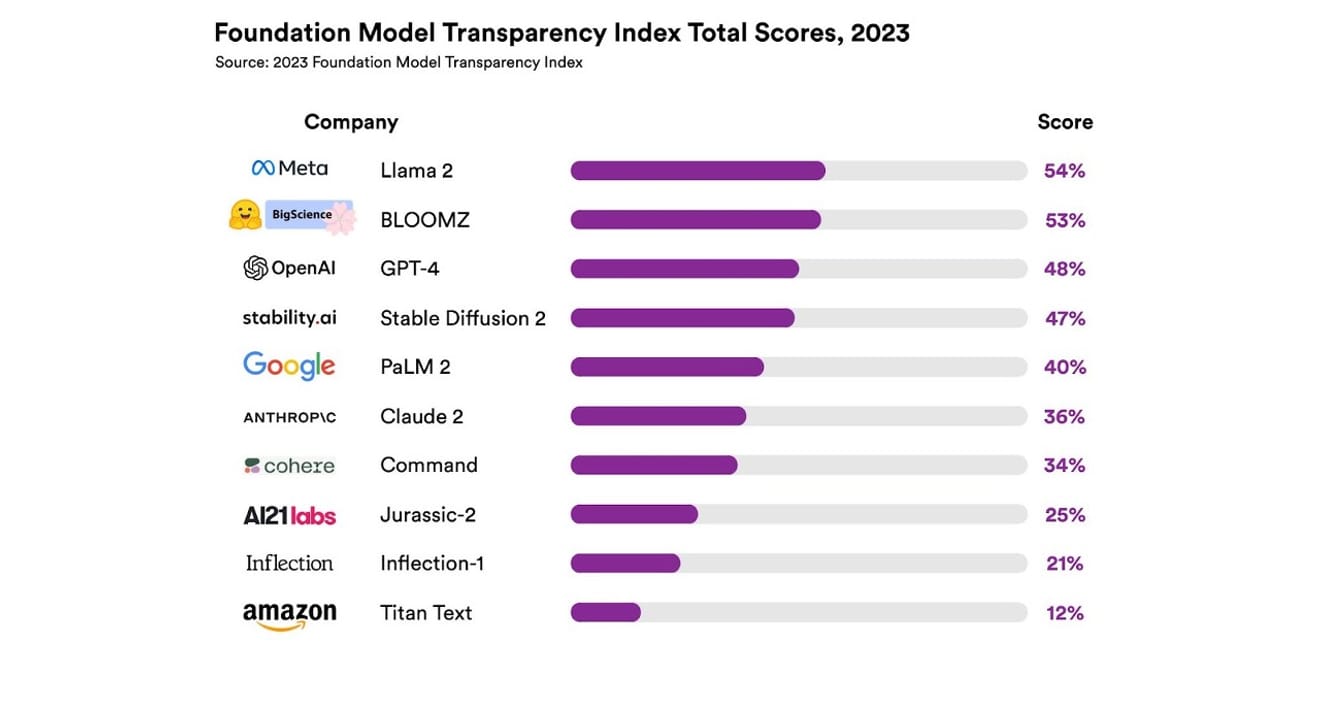
Mereka meneliti total 10 sistem AI yang berbeda, sebagian besar merupakan model bahasa besar (Large Language Model/LLM) seperti yang digunakan dalam ChatGPT dan chatbot lainnya. Ini termasuk model komersial yang banyak digunakan seperti GPT-4 dari OpenAI, PaLM 2 dari Google, dan Titan Text dari Amazon. Mereka mengevaluasi keterbukaan (transparency) berdasarkan 13 kriteria, termasuk seberapa transparan pengembang dalam mengungkapkan data yang digunakan untuk melatih model (termasuk metode pengumpulan dan anotasi data, serta apakah ada materi berhak cipta), serta keterbukaan informasi tentang perangkat keras yang digunakan untuk melatih dan menjalankan model, kerangka kerja perangkat lunak yang digunakan, dan konsumsi energi proyek.
Hasilnya menunjukkan bahwa tidak ada model AI yang mencapai lebih dari 54% pada skala transparansi untuk semua kriteria yang disebutkan. Secara keseluruhan, Titan Text dari Amazon dinilai sebagai yang paling tidak transparan, sedangkan Llama 2 dari Meta terpilih sebagai yang paling terbuka. Yang menarik adalah Llama 2, yang merupakan perwakilan utama dari model open-source dan closed-source yang belakangan ini menjadi sorotan, meskipun open-source, namun tidak mengungkapkan data yang digunakan untuk pelatihan, metode pengumpulan dan kurasi data, dan lain sebagainya. Dengan kata lain, meskipun pengaruh AI terhadap masyarakat kita semakin besar, kurangnya transparansi dalam industri ini merupakan fenomena yang umum dan berkelanjutan.
Ini menunjukkan risiko bahwa industri AI segera akan menjadi bidang yang berorientasi pada keuntungan daripada kemajuan ilmiah, dan berpotensi mengarah pada masa depan yang eksklusif yang didominasi oleh perusahaan tertentu.

Eric Lee/Bloomberg via Getty Images
Sam Altman, CEO OpenAI, telah secara terbuka bertemu dengan para pembuat kebijakan di seluruh dunia untuk menjelaskan kecerdasan baru yang tidak biasa ini kepada mereka dan menawarkan bantuan dalam mengkonkritkan peraturan yang relevan. Namun, meskipun pada prinsipnya mendukung gagasan sebuah badan internasional untuk mengawasi AI, ia juga percaya bahwa beberapa aturan yang terbatas, seperti melarang semua materi berhak cipta dalam kumpulan data, dapat menjadi penghalang yang tidak adil. Jelas terlihat bahwa 'keterbukaan' yang tersirat dalam nama perusahaan OpenAI telah berubah dari transparansi radikal yang diusung pada awal berdirinya.
Namun, perlu dicatat bahwa hasil laporan Stanford ini juga menunjukkan bahwa tidak perlu bagi setiap perusahaan untuk merahasiakan model mereka demi persaingan. Karena hasil ini juga merupakan indikator kinerja buruk hampir semua perusahaan. Misalnya, tidak ada perusahaan yang memberikan statistik tentang berapa banyak pengguna yang bergantung pada model mereka atau bagian pasar atau wilayah geografis tempat model mereka digunakan.
Di antara organisasi yang menganut prinsip open-source, ada pepatah yang berbunyi, 'Banyak mata membuat semua bug terlihat.' (Hukum Linus) Jumlah yang banyak membantu dalam menemukan dan memperbaiki masalah serta menemukan masalah yang dapat diperbaiki.
Namun, praktik open-source juga cenderung secara bertahap mengurangi status sosial dan pengakuan nilai dari perusahaan yang terbuka, baik di dalam maupun di luar perusahaan, sehingga penekanan yang berlebihan tidaklah terlalu berarti. Oleh karena itu, daripada terpaku pada kerangka model terbuka atau tertutup, akan lebih baik untuk memfokuskan diskusi pada peningkatan bertahap akses eksternal terhadap ‘data’ yang menjadi dasar model AI.

Dalam kemajuan ilmiah, menjamin keterulangan (Reproducibility) hasil penelitian tertentu sangatlah penting. Dengan menjamin transparansi terhadap komponen utama dari pembuatan setiap model, kita dapat mencegah industri terjebak dalam situasi eksklusif dan stagnan. Dan ini harus menjadi prioritas utama yang dipertimbangkan dalam konteks saat ini dan masa depan, di mana teknologi AI dengan cepat meresap ke dalam semua sektor industri.
Penting bagi jurnalis dan ilmuwan untuk memahami data, dan transparansi merupakan prasyarat untuk upaya kebijakan yang terencana bagi para pembuat kebijakan. Bagi masyarakat umum, transparansi juga penting karena sebagai pengguna akhir sistem AI, mereka dapat menjadi pelaku atau korban dari masalah potensial yang terkait dengan hak kekayaan intelektual, penggunaan energi, dan bias. Sam Altman berpendapat bahwa risiko kepunahan manusia akibat AI harus menjadi prioritas global seperti halnya risiko sosial skala besar lainnya seperti pandemi dan perang nuklir. Namun, kita tidak boleh melupakan bahwa kelangsungan hidup masyarakat kita yang mampu mempertahankan hubungan yang sehat dengan AI yang sedang berkembang adalah prasyarat sebelum mencapai skenario berbahaya yang ia sebutkan.
*Artikel ini adalah salinan asli dari kolom yang diterbitkan di Koran Elektronik pada tanggal 23 Oktober 2023.
Referensi
Komentar0