Badania opublikowane 18 dnia przez zespół naukowców ze Stanford University ujawniają, jak głęboka i potencjalnie niebezpieczna jest tajemnica stojąca za GPT-4 i innymi najnowocześniejszymi systemami sztucznej inteligencji.
Wprowadzenie indeksu przejrzystości modeli podstawowych, Uniwersytet Stanforda
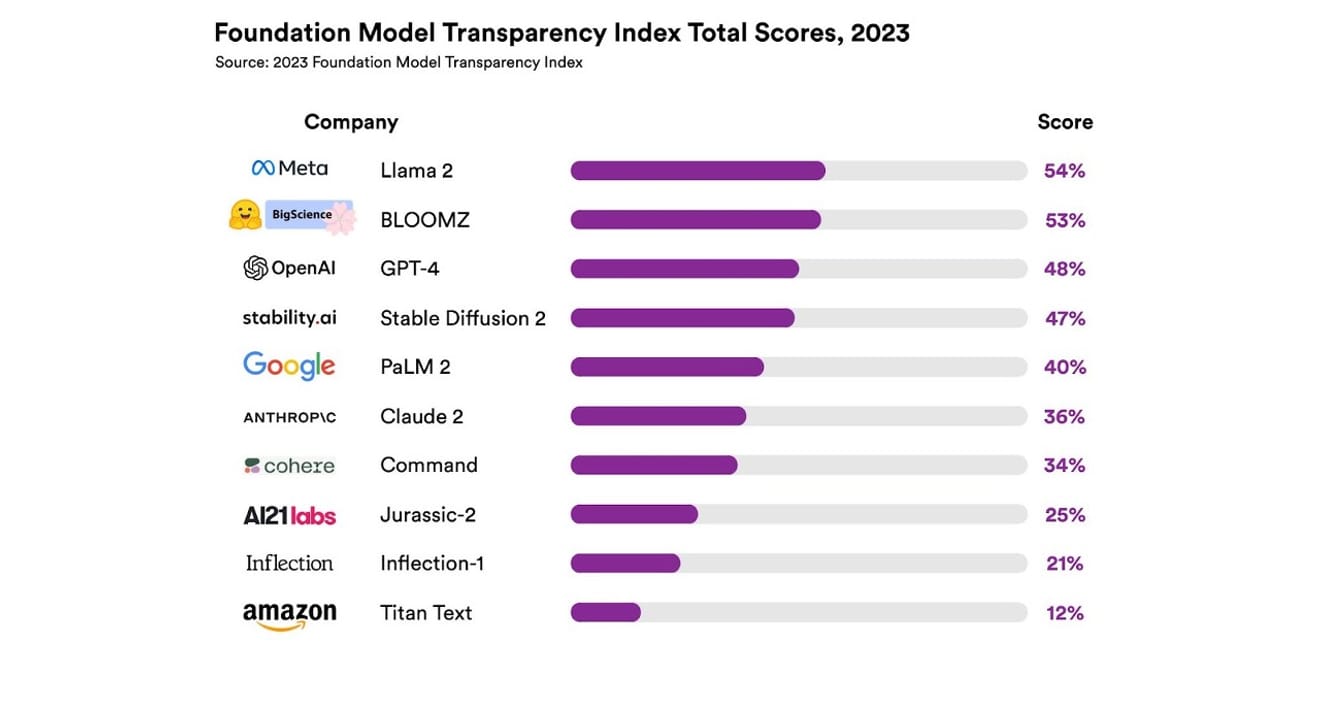
Zbadali oni łącznie 10 różnych systemów sztucznej inteligencji, z których większość stanowiły duże modele językowe, takie jak te wykorzystywane w ChatGPT i innych chatbotach. Wśród nich znalazły się szeroko rozpowszechnione komercyjne modele, takie jak GPT-4 od OpenAI, PaLM 2 od Google i Titan Text od Amazon. Ocenili oni otwartość modeli na podstawie 13 kryteriów, w tym stopnia przejrzystości ujawnianych przez twórców informacji na temat danych użytych do trenowania modeli (w tym metody gromadzenia i adnotowania danych oraz informacje o tym, czy materiały objęte prawami autorskimi zostały uwzględnione). Ponadto zbadali, czy twórcy ujawnili informacje na temat sprzętu użytego do trenowania i uruchamiania modeli, użytych frameworków programistycznych oraz zużycia energii w ramach projektu.
Wyniki pokazały, że żaden z modeli AI nie osiągnął ponad 54% w skali przejrzystości we wszystkich wymienionych kryteriach. Ogólnie rzecz biorąc, Titan Text od Amazona został oceniony jako najmniej przejrzysty, a Llama 2 od Meta jako najbardziej otwarty. Co ciekawe, Llama 2, który jest przedstawicielem niedawno popularnej opozycji między modelami otwartymi i zamkniętymi, mimo że jest modelem open source, nie ujawnił danych użytych do trenowania, a także metod gromadzenia i kurationu danych. Oznacza to, że pomimo rosnącego wpływu sztucznej inteligencji na nasze społeczeństwo, brak przejrzystości w branży jest zjawiskiem powszechnym i ciągłym.
To oznacza, że branża AI wkrótce może stać się obszarem skupionym nie na rozwoju naukowym, a na zyskach, co może prowadzić do przyszłości zdominowanej przez konkretne firmy i charakteryzującej się monopolizacją.

Eric Lee/Bloomberg via Getty Images
Sam Altman, dyrektor generalny OpenAI, już spotyka się z decydentami na całym świecie, aktywnie wyjaśniając im tę nową i nieznaną inteligencję oraz wyrażając gotowość do pomocy w konkretyzacji regulacji w tej dziedzinie. Chociaż zasadniczo popiera ideę międzynarodowej organizacji nadzorującej AI, uważa również, że niektóre ograniczenia, takie jak zakaz wszystkich materiałów chronionych prawami autorskimi w zbiorach danych, mogą stanowić niesprawiedliwą przeszkodę. Jest to jasny dowód na to, że „otwartość” zawarta w nazwie firmy OpenAI wyraźnie odbiega od radykalnej przejrzystości, którą prezentowano na początku jej działalności.
Jednakże, jak pokazują wyniki raportu ze Stanford, warto zwrócić uwagę na fakt, że nie ma potrzeby utrzymywania modeli w tajemnicy w celu konkurowania. Wyniki te są bowiem wskaźnikiem słabej kondycji niemal wszystkich firm. Na przykład, żadna firma nie udostępnia danych statystycznych na temat liczby użytkowników korzystających z ich modeli ani regionów lub segmentów rynku, w których są one wykorzystywane.
W organizacjach opartych na zasadach open source krąży przysłowie: „Im więcej oczu, tym mniej błędów”. (Prawo Linusa) Surowe liczby pomagają w identyfikacji i rozwiązywaniu problemów, a także w znajdowaniu problemów, które można naprawić.
Jednak praktyki open source mają również tendencję do stopniowego obniżania pozycji społecznej i uznania wartości zarówno wewnątrz, jak i na zewnątrz firm stosujących zasadę otwartości, więc bezwarunkowe podkreślanie tej zasady nie ma większego sensu. Dlatego zamiast skupiać się na ramie „model otwarty vs. zamknięty”, lepiej jest skupić uwagę na stopniowym zwiększaniu zewnętrznego dostępu do „danych” będących podstawą modeli AI.

W rozwoju nauki istotne jest zapewnienie powtarzalności (Reproducibility) wyników badań, czyli możliwość ich odtworzenia. Bez konkretyzacji sposobów zapewnienia przejrzystości kluczowych komponentów tworzenia każdego modelu, branża prawdopodobnie utknęłaby w zamkniętym i stagnacyjnym środowisku monopolistycznym. A to w obecnej sytuacji, kiedy technologie AI szybko wnikają do wszystkich dziedzin gospodarki, i w przyszłości, powinno być traktowane jako priorytet.
Dla dziennikarzy i naukowców zrozumienie danych stało się kluczowe, a dla decydentów przejrzystość jest warunkiem wstępnym planowanych działań politycznych. Dla społeczeństwa przejrzystość jest również ważna, ponieważ jako ostateczni użytkownicy systemów AI mogą być sprawcami lub ofiarami potencjalnych problemów związanych z prawami własności intelektualnej, zużyciem energii oraz stronniczością. Sam Altman twierdzi, że ryzyko wyginięcia ludzkości w wyniku sztucznej inteligencji powinno być traktowane jako jeden z globalnych priorytetów, na równi z zagrożeniami takimi jak epidemie czy wojny nuklearne. Jednakże, zanim dojdzie do sytuacji, o której wspomina, należy pamiętać, że warunkiem wstępnym jest przetrwanie społeczeństwa, które utrzymuje zdrową relację z rozwijającą się sztuczną inteligencją.
*Ten artykuł jest oryginalną wersją kolumny opublikowanej w dzienniku elektronicznym „Dziennik Elektroniczny” z dnia 23 października 2023 roku.
Bibliografia
Komentarze0